Optimizing performance of the Krutrim foundational LLM on Gaudi-2
The mission of making AI accessible to all Indians has been at the core of what we are building. Affordable AI solutions can make AI accessible.
At Krutrim, we are working on the complete AI computing stack with a focus on driving efficiency across model pre-training, inferencing and fine-tuning. The key operating metric being maximized across all these workload types is performance/cost (perf/₹).
We are also creating our own Krutrim Cloud stack which allows developers to choose from a variety of silicon hardware options across providers such as Nvidia, Intel and AMD amongst others for their AI model development needs. Towards this end, we are working with different hardware providers to drive optimizations so that developers can extract the best perf/₹ for their tasks.
Our recent work with Intel on optimizing model pre-training, inference and fine-tuning for perf/₹ is a case in point. Some learnings from our optimization efforts below.
Krutrim – Intel optimization effort
Krutrim’s AI engineering team and cloudstack development team worked alongside Intel’s Gaudi-2 team to optimize perf/₹ for a variety of workloads. All of this work was done on the existing Krutrim foundational model and powers the Krutrim personal assistant.
The Krutrim LLM model has various unique attributes as shared during the launch event, as it has inherent knowledge of Indian languages and has generative capabilities across 11 languages.
Some of the key optimizations implemented by Krutrim and the Intel Habana team, (apart from firmware changes by the Intel Habana team), include:
- For group attention, the Q and KV shapes are not the same, therefore the Q heads need to be divided into groups, and assigned to a single KV. This was achieved by repeating key-value pairs n_rep times, where n_rep corresponds to the number of query heads that share the same key-value pair.
- Split matrix dimension to improve computational efficiency
- Enabled KV buckets to optimize for long output prompt instead of reusing KV cache
2. Pre-training optimizations: We tried pre-training at a variety of node cluster sizes. We saw a near linear scaling in training performance as we scale the number of nodes in the cluster training. The major loss in pre-training efficiencies occurs due to node failures and the time it takes to detect and auto-recover & then re-start from the previous checkpoint.
We enabled improvement of auto-recovery from node failures by optimizing the time between restarts, change in training script amongst various other changes.
3. Fine-tuning optimization: Enabled support for 4K sequence length for PEFT LoRA fine-tuning, by adding gradient checkpointing to save memory used.
These optimizations together with the software upgrade by the Gaudi-2 team (From 1.13 to 1.14) helped enhance the overall perf/₹ performance across these tasks.
Perf/₹ comparison
Pre-training, inferencing and fine-tuning experiments were run on the Krutrim foundational LLM using both H100 and Gaudi-2 and the results were compared. The setup is explained below.
- For training: Performance was measured in terms of the time to train over a set of nodes (8-GPUs per Node).
- For inference: Performance was measured for the following setup
- Batch size: 64
- Input & Output tokens: 128 each
- Precision: FP16
- For H100, the TensorRT LLM framework was applied to the model architecture to get the benefit of the optimizations
Post optimization comparison of performance for pre-training and inference tasks are shown in the chart below. Note that performance of H100 is indexed to 1 and Gaudi-2 performance is normalized accordingly.
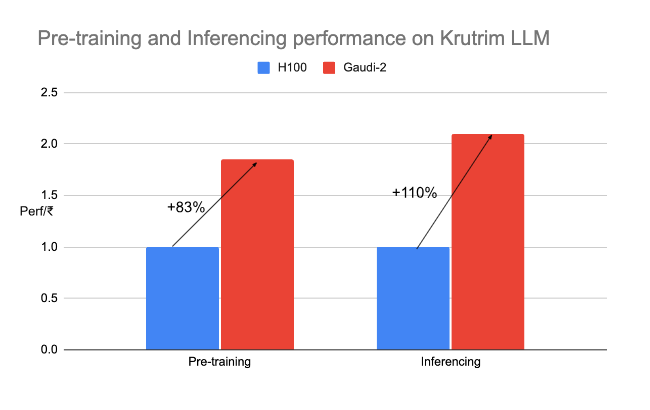
The joint effort of Krutrim and Intel has helped deliver significantly better performance/cost across all these model development workloads. We will continue to work towards extracting more efficiencies from the Gaudi family of accelerators and make AI more accessible.